")
Продолжаем обзор книг по питону для новичков. И сегодня на очереди «Python это просто» Нилаба Нисчала.
Пошаговое руководство по программированию и анализу данных. Изначально я не планировал делать на неё обзор, так как анализ данных — это конкретная специализация, а я стараюсь обходить стороной специализированную литературу.
Но полистав книгу я понял, что она в основном про Python. Плюс небольшой уклон в аналитику ближе к концу. Поэтому книга на обзоре.
Итак, автор — Нилаб Нисчал — маркетолог и ведущий аналитик данных, что вызывает дополнительный интерес, так как авторов с таким опытом мы еще не встречали.
И так как речь про аналитику, то примеры здесь приводятся в среде Jupyter Notebook — это специальное программное обеспечение для запуска питона в браузере. Его в основном используют как раз аналитики и дата сайнтисты.
Погружение в Python
Книга начинается с информации о науке о данных и, в целом, повествование мне понравилось, автор пишет легко и непринужденно. Рассказывает о природе данных, о языках программирования и о программировании на Python в целом. Получилась хорошая такая вводная глава.
Далее нас знакомят с Питоном и тут тоже всё очень лаконично. Я бы сказал, что повествование напомнило мне Тони Гэддиса. Мы медленно и аккуратно входим в программирование без каких-либо сложных концепций. Завершается вторая глава установкой Анаконды. Анаконда — это такой дистрибутив, который содержит Python, а также набор библиотек для анализа данных. В том числе Jupyter Notebook, который я упомянул ранее.
И сразу после установки необходимых программ автор начинает погружать нас в Python — показывает операции с числами и строками, даёт немного списков и кортежей.
Примечательно, что Нилаб приводит описание функции print(), за которое я ругал некоторых российских авторов в прошлых обзорах. Но здесь, во-первых, мы более плавно подходим к описанию, а во-вторых, автор очень хорошо объясняет, что и как работает в принте. А не просто вываливает на вас фрагмент документации.
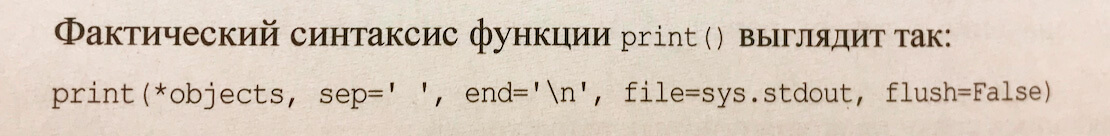
Еще через пару глав мы подбираемся к условиям и циклам, и автор вполне уместно вводит блок схемы, которые дают понимание того, как работают более сложные концепции программирования. Возможно его примеры не самые наглядные, но сам подход правильный:
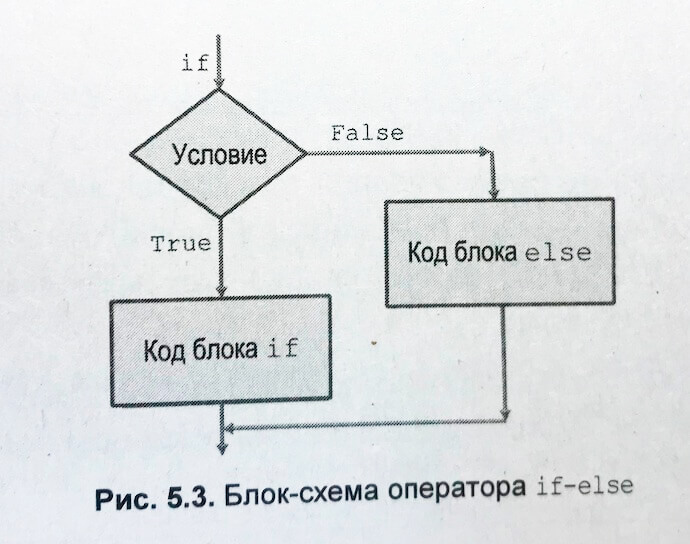
Также он приводит пример вполне реальной бизнесовой задачи, которая начинается со слов: «Перед праздником в торговом центре объявили распродажу. При покупке электронных товаров вам предлагается скидка 20% ...». Это классная, понятная и нескучная задача, на примере которой объясняются условия.
Далее автор приводит более сложную бизнес-задачу и более сложный пример использования условий и, к моему сожалению, допускает ошибку. Причем новичковую:
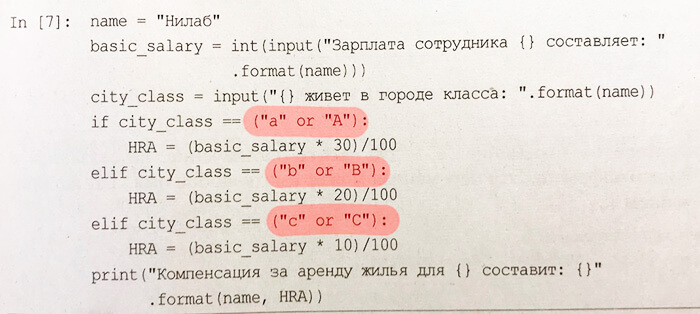
Давайте разберемся в чем тут дело. Автор хочет сделать так, чтобы программа могла принимать и строчную, и заглавную буквы. Не важно, что введет пользователь.
Но в таком выражении сперва будет выполнен оператор or в скобках, который вернет первый вариант, то есть строчную букву. А значит сравнение всегда будет происходить только с ней. И если пользователь введет заглавную, то получит ошибку NameError.
Правильно данное сравнение нужно записать так:
if city_class == "a" or city_class == "A":
...
elif city_class == "b" or city_class == "B":
...
elif city_class == "c" or city_class == "C":
...Или с использованием кортежей или множеств:
if city_class in ("a", "A"):
...
elif city_class in {"b", "B"}:
...
elif city_class in "cC":
...Или можно привести переменную city_class к нижнему регистру и сравнивать с одной буквой:
city_class = city_class.lower()
if city_class == "a":
...
elif city_class == "b":
...
elif city_class == "c":
...В общем, это довольно досадная ошибка, которую не ожидаешь увидеть в книге практикующего программиста.
В итоге я написал Нилабу письмо с указанием на ошибку, а также сделал Pull request в официальный github-репозиторий книги. То есть сам исправил баг и отправил код автору.
Правда на момент написания данного обзора, Нилаб еще не принял мои изменения в репозиторий. Будем надеятся, что он просто занят и сделает это позже.
А мы же пойдём дальше — к 6 главе, где нам рассказывают про функции. Тут всё также — хорошее описание и классные живые примеры. Единственное автор почему-то в названиях использует смешанную нотацию — CamelCase и Unserscore сразу, и это довольно странно.
Также я заметил не совсем корректное использование скобок в условиях и несколько опечаток в коде, но они совсем некритичные.
В какой-то момент автор переходит на объяснение генераторов и оператора yield. Это не совсем новичковая тема, но сам yield объясняется понятно. В целом пару страниц в книге можно спокойно пропустить, хуже не будет.
Дале мы подходим к 7 главе и в ней Нилаб дает первый проект. Фактически — это набор заданий, в которых нужно вывести в консоль рисунки с помощью циклов и функций:

Я раньше скептически относился к таким рисункам, так как они довольно далеки от реальных бизнес-задач.
Но потом дал несколько таких упражнений в нашем курсе по питону и всё оказалось не так просто. Такие задачи классно развивают именно понимание циклов и функций, в том числе вложенных. Там реально приходится думать головой. Поэтому в качестве развития навыков программирования они будут полезны.
Рекомендую выполнить их все. В книге их около 20. Причем можете использовать как цикл for, так и while, чтобы потренировать логику.
Далее мы переходим к восьмой главе про строки, списки, кортежи, множества и конечно же словари. А д евятая глава посвящена вводу-выводу, а также содержит более подробную информацию о форматировании, включая f-строки, плюс примеры работы с файлами.
Проекты
Десятая глава снова посвящена проекту. На этот раз нам предлагается обработать изображения с помощью библиотеки Pillow. В рамках этой главы мы пишем программу, которая пробегается по всем файлам в каталоге с фотографиями и уменьшает их размер. Вполне реальная задача. Я с ней много раз сталкивался на практике.
Следующая глава посвящена классам и ООП. Не сказал бы, что там очень подробно, но в целом общее представление о классах у вас появится.
Далее мы переходим к исключениям, работе с модулями и пакетами. Кстати, хочу напомнить, что в этой книге весь код мы пишем в Юпитер Блокнотах и это важно.
Например, в проекте про обработку изображений мы используем библиотеку Pillow, но при этом не устанавливаем её. А это вообще-то, внешняя библиотека и если попытаться запустить приведенный код из чистого Python, то у вас ничего не получится. Но в Юпитере всё будет работать без проблем, так как там Pillow уже установлен.
В 14 главе мы пишем еще один проект, на этот раз с помощью Tkinter. И на этом общее изучение Питона заканчивается, и мы переходим к аналитике.
Аналитика на Python
И начинаем с библиотеки NumPy, которая используется для быстрых математических и научных вычислений. В 15 и 16 главах идет общее описание библиотеки с разными примерами кода, пока без какого-то явного практического использования.
В 17 главе нас дополнительно знакомят с библиотекой Pandas, которую используют аналтилики в своей работе. Библиотека нужна для обработки большого количества данных.
Глава также посвящена знакомству с библиотекой и некоторым несложным приёмам работы с ней.
А вот 18 глава называется «Pandas в действии» и в ней автор приводит уже более серьезные и полезные вычисления: включая группировки по категориям, сортировку и так далее.
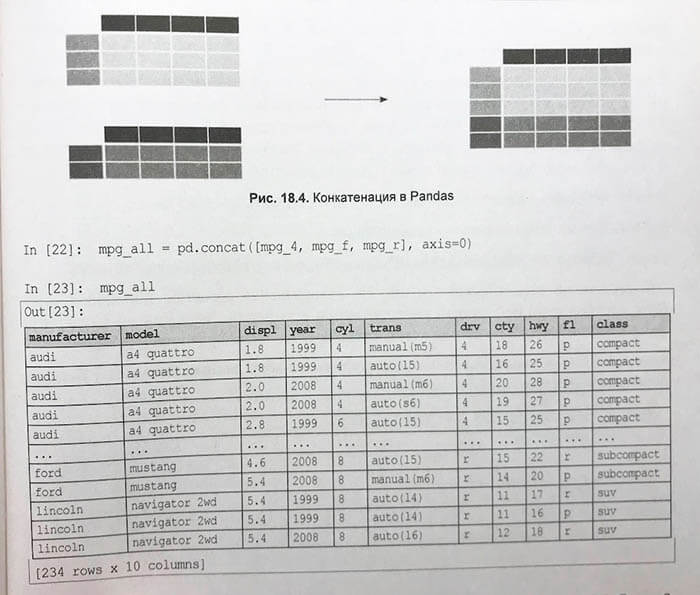
В 19 главе нас знакомят с визуализацией данных на базе pandas и matplotlib. Собственно визуализации и построению графиков автор посвящает всю оставшуюся книгу.
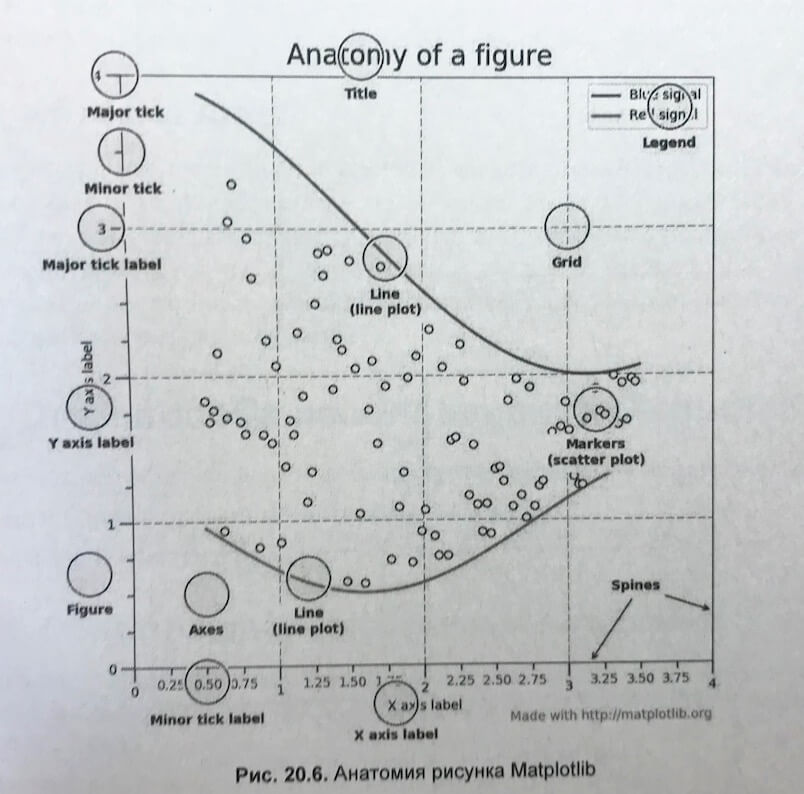
И целом книга мне понравилась, за исключением пары моментов, про которые я сказал ранее, она отлично подходит для начинающих аналитиков на Питоне. Если вы видите себя в этой области, то можете смело её брать. Для web-разработчиков или для тех, кто хочет писать оконные приложения она не подойдет. А вот чтобы вкатиться в Data Science — вполне ОК. Рекомендую.
